移动端APM网络监控及优化
1.简介
本项目上线前,网络监控只是针对后端服务的监控,但是,对于移动端用户而言,用户手机性能和网络环境复杂,用户的真实体验和后台服务监控之间存在很大差异,因此,我们建立了一套基于用户层面的实时、多维度的网络监控系统,并建立了针对端上的错误率、劫持率、性能评估标准.
2.系统设计
根据移动端网络错误的特点,计算错误率时, 将其划分为三类:
- 网络层错误(错误发生在三次握手,SSL校验,数据传输过程中,如ConnectException)
- HTTP响应错误(服务端已明确返回错误码,如404)
- 解析错误(服务端返回200,但是,数据格式有问题,导致前端无法正确解析)
由于重试机制的存在,我们为每次重试都分配了唯一的TraceId,这一组的重试数据,拥有一个统一SessionId.同时,在计算错误率时,我们只按照一组数据中的最后一次请求的结果,评判该次用户网络行为成功或者失败.
维度信息设计: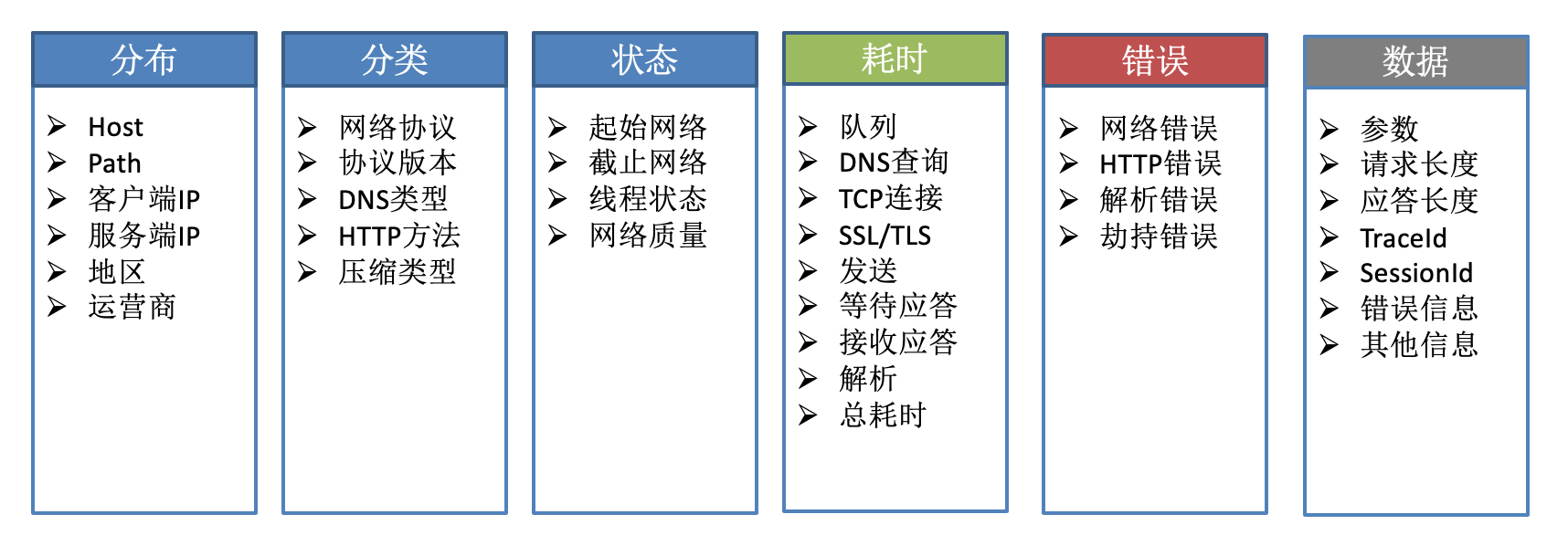
在后端存储的字段里,除了上述网络字段,还包括APM平台和用户设备的基础字段信息,这里就不一一赘述.
2.1 SDK设计
端上网络请求频繁,数据采样需要考虑对手机性能影响,同时,也要保证数据的准确可分析,我们采样的措施有:
- 云控采样 云控下发采样指令,一次启动至退出作为采样单元,动态控制数据量
- 合并压缩 网络行为产生的数据,会进行缓存,在达到时间或者数量的阈值时,进行投递,投递时进行批量压缩投递
- 失败重投 投递失败的数据,会进行本地存储,下次启动尝试投递
由于数据投递可能滞后,分析时,可使用1.端上发生时间2.投递到达后端时间,两个时间戳进行查询分析
2.2 后端设计
在后端系统设计中,需要支持高数据实时性、较大的存储数据量、灵活的查询和准确及时的报警。具体措施有:
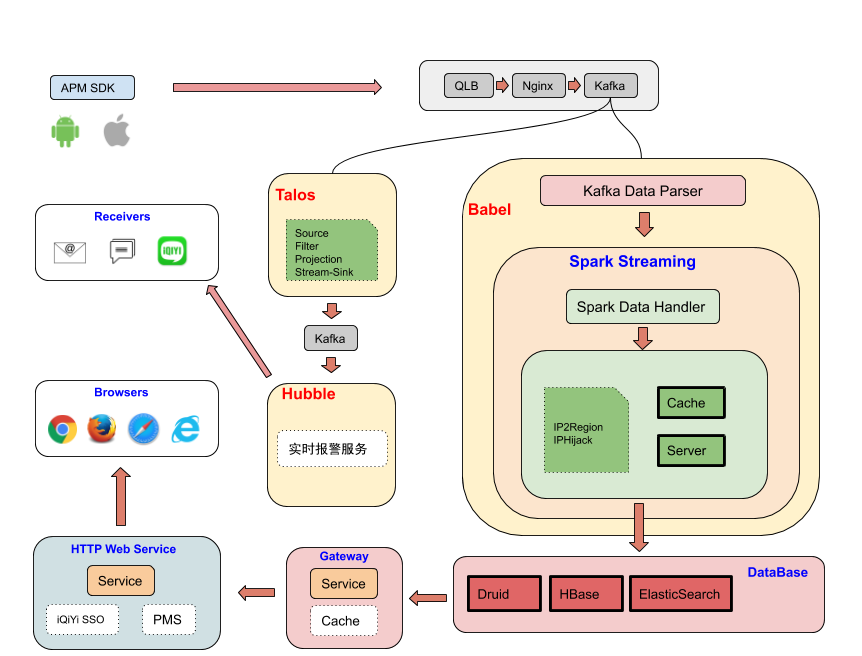
- 实时性 采样Spark Streaming实时消费kafka数据
- 存储 存储主要使用Elastic Search(ES).但是,由于ES对资源消耗比较大,
我们使用Hbase存储日志性字段信息,使用Druid进行全量的指标统计. - 报警 我们采用同环比和固定阈值的方式进行报警,具体报警粒度为
platform+version+host+path,通过订阅,可及时将相关线上问题,通过邮件、短信、热聊、电话等形式通知责任人.收到报警信息后,可通过APM Web平台,查看详细的报错信息.
2.3 Web设计
Web展现错误率监控时,主要考虑是:
- 快速查看整体状态
- 查看所有业务
错误数/错误率/请求数的top列表 - 可分析具体原因;
基于上述三个基本出发点,我们设计的页面有:
- 首页 首页拥有
错误率曲线和中国地图,分别展示实时整体和各省的网络错误率状态 - 错误分布 将Host+path的组合,进行
错误数/错误率/请求数进行排列,可自由按照三个维度进行正倒序排列 占比详情 属于整体的聚合数据,将选中的某个请求的错误信息进行聚合,以饼图展现,包括地区运营商、服务器IP、错误码、版本等
排查问题时,如果错误码集中,可以判断具体错误类型; 如果服务器IP集中,可以判断出问题的服务器信息.
详情信息 单个请求信息,详情信息里包含了所有的信息,包括维度信息和日志型信息,用于分析单个请求的具体信息.
除了错误率页面,还有耗时分析和劫持分析, 耗时分析用于查询请求总体及各阶段耗时信息,劫持分析用于查询具体请求的劫持情况.
3.优化
网络监控和标准建立完成后,我们又引入一些优化方案,对错误率/劫持率/性能进行了优化.
3.1 DNS优化
在HTTP协议里,DNS作用是解析出正确的IP地址,网络请求首先进行DNS解析,然后根据IP进行后续流程,所以,DNS优化很关键.
DNS优化主要从以下几个点考虑优化:
- DNS劫持 在移动请求里,劫持指的是运营商DNS服务器被攻击,域名解析时返回了错误的IP地址,导致请求失败
- DNS TTL过长 TTL即域名解析记录在DNS服务器缓存时间.各地运营商DNS TTL时间也不尽相同,有些偏远地区TTL时间过长,可能导致两个问题:
1.公司正常下线了某些服务器,运营商可能长时间未更新缓存
2.后台服务故障,需要及时更新服务器列表 - 跨运营商 跨运营商可能导致访问慢
- LocalDNS获取失败 在网络较差或者特殊情况下,LocalDNS信息可能获取失败或者时间过长
综上,我们优化措施有:
3.1.1 三层缓存
建立内存+网络+本地持久化的三层缓存机制,内存缓存设置一定的时效,网络不通时,会使用本地的持久化缓存,好处在于:
- 快速获取域名DNS解析信息
- 网络较差或者获取LocalDNS失败时,可以从尝试本地获取结果
- 可记录上次请求时,成功的IP,会记录其成功率和性能数据,下次重建连接,优先使用上次成功率较高,性能较好的IP
3.1.1 HTTPDNS
HTTPDNS是业内比较完善DNS优化方案,通过HTTPS请求,主动去自己的基础平台拉取域名对应的IP信息,好处也显而易见
- 防劫持,由于接口存在于自己后台,不存在运营商劫持问题
- 高时效,如果后台服务ip有更新,可以立刻更新上线,解决了运营商TTL问题
- 结果最优,HTTPDNS可以根据当前后台服务状况,选择最优的IP排序返回
上线后,观察到劫持率下降了80%.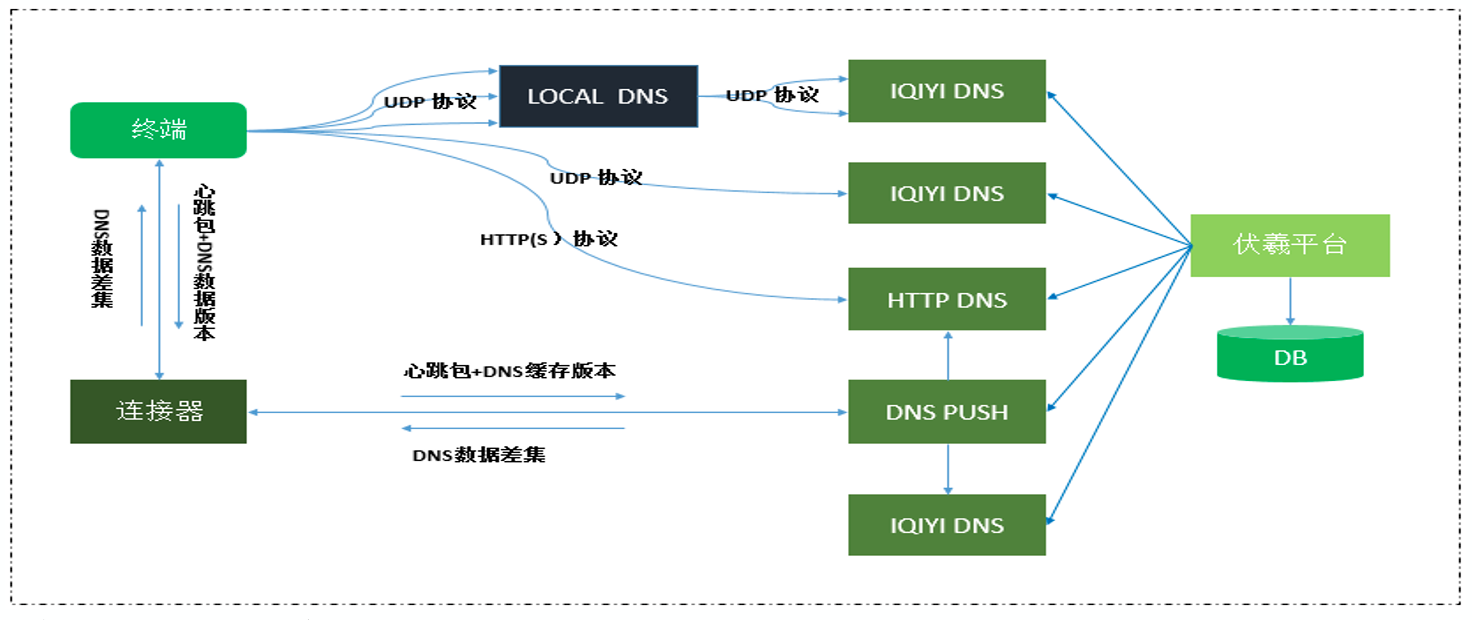
在使用HTTPDNS时,同时设计了降级方案,如果HTTPDNS不可用,会降级为LocalDNS;HTTPDNS同时也存在时效性,设计有超时机制,并且在网络环境改变时,会主动更新.
3.2 弱网优化
移动端上网络环境复杂,用户随时可能处于弱网环境下,为了保证用户体验,需要在弱网环境下进行特殊优化
3.2.1 弱网模型
首先,需要进行弱网判断,甄别出用户当前所处的网络状况
计算标准:
网络流畅分级模型,参考了多个维度数据,包括上行/下行网速、请求失败率、网络延迟等.针对不同维度的因素,设置不同天阈值,综合多个网络因素等级,最终确认整体网络等级.目前策略里,只要有一个因素落在VERY_POOR,POOR区间,则认为是弱网环境
等级划分:
| 名称 | 取值 | 网络状况说明 | |
|---|---|---|---|
| VERY_POOR | 0 | 非常差 | |
| POOR | 1 | 较差 | |
| MODERATE | 2 | 一般 | |
| GOOD | 3 | 较好 | |
| EXCELLENT | 4 | 非常好 | |
| UNKNOWN | 5 | 未知 |
根据网速值,划分为六个等级,网络状态会投递至后端,判断时,在value<=1,表示弱网
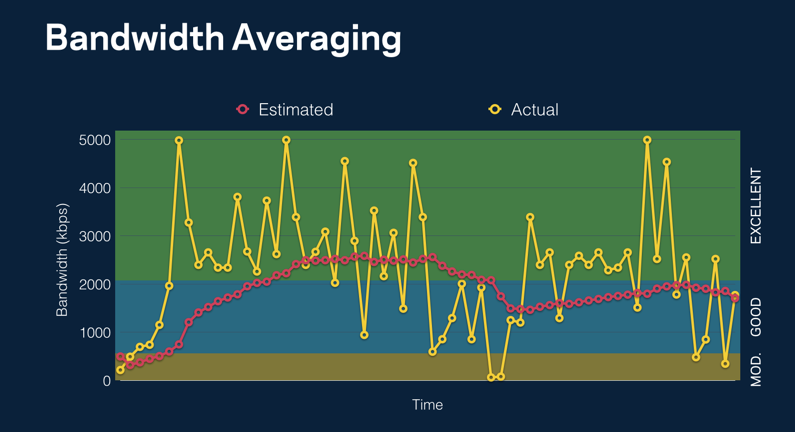
前端计算的网速数据波动比较大,所以,我们参考facebook方案,对网速数据进行了处理, 归一化后的拟合效果:
3.2.2 弱网优化
在建立好弱网模型后,我们又进行了一系列的优化,包括:
- Brotli压缩 Brotli相对Gzip压缩效率提高17-25%,不过由于其更耗服务端资源,前后台约定,会在弱网下使用Brotli压缩
- 减小并发 网络库中,存在网络请求线程池,弱网下,减小并发数
- 建立优先级 重要域名使用优先级更高线程池处理
- 减少响应数据 对返回数据大小进行缩减,比如,页面相关的,减少分页数,减少card数
3.3 网关方案
Ares网关方案,通过后台一个中转服务,分发请求,端上所有请求都复用现有的长连接,相当于间接实现了域名收敛.
相对正常Http请求,其优势有:
- 多域名连接共享,实现0RTT多路复用
- 避免了DNS解析,防止DNS劫持
- protobuf编码私有协议,节省流量
在一个接口上A/B实验的结果看, 平均请求耗时从595ms降低至371ms,成功率也有所提升
网络架构图: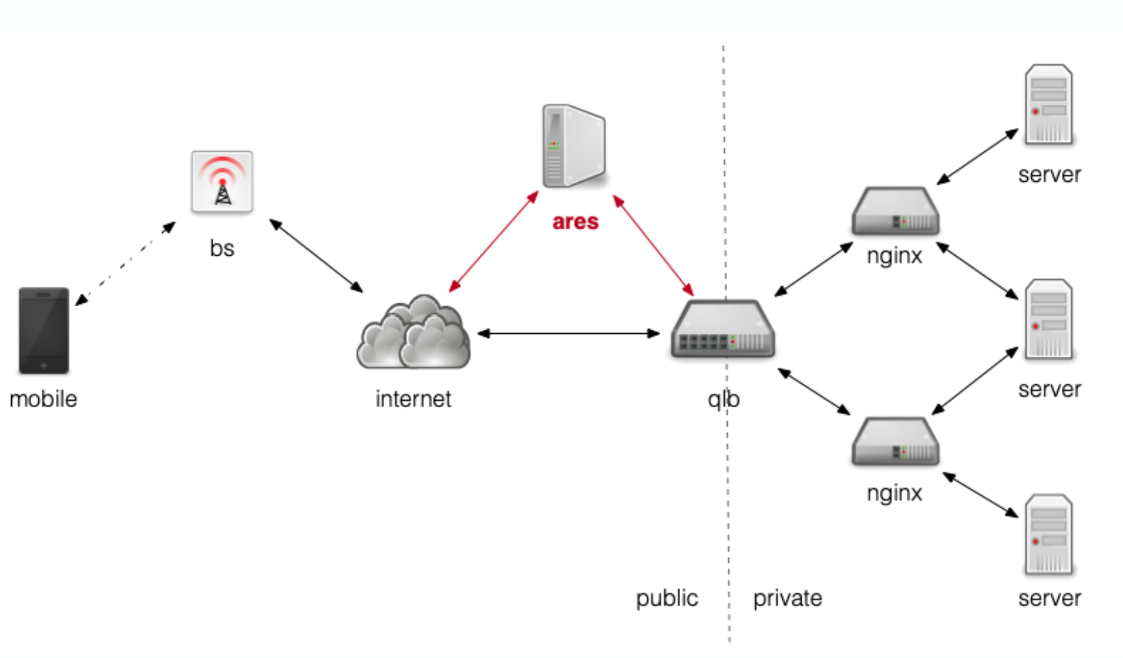
3.4 超级管道兜底
公司自研的基于HTTP网关的代理服务
前端:通过一个统一的域名进行请求,使用该服务的请求,可以将其请求信息,作为参数拼接在统一的请求里
后端:通过中转服务,将不同的请求分发,并且,会进行异地容灾分发,减小单个地区服务器故障造成的影响
在一次线上故障时,使用超级管道的接口错误率3.95%,未使用的错误率高达28.96%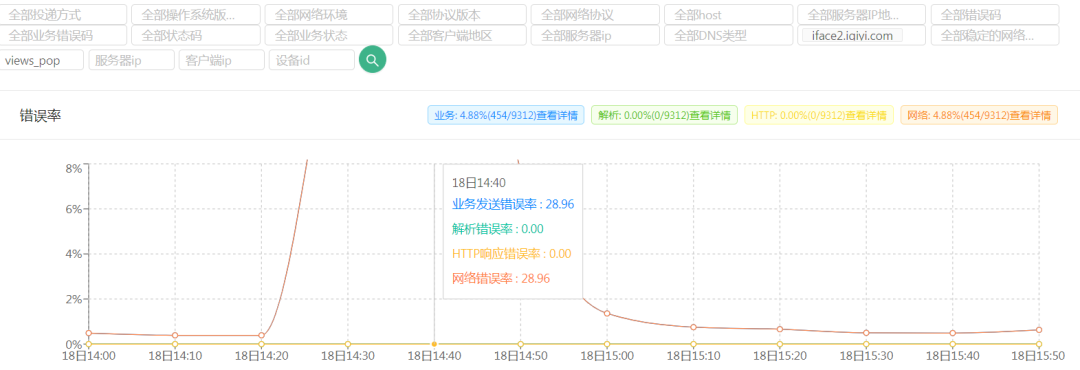
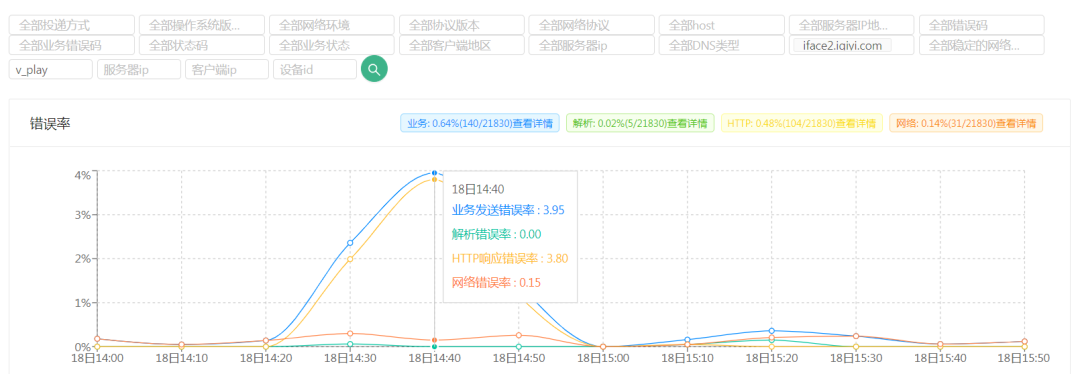
3.5 合理重试
对于用户而已,需要最终的成功的结果,所以,请求失败后,内部进行重试是十分有必要的,一定的重试,可以有效降低错误率.
我们使用的重试策略有:
- 原样重试, 业务方可配置重试次数, 防止网络波动引起的请求失败
- HTTPS降级重试, 如HTTS降级为HTTP重试, 防止SSLException导致的请求失败
- HTTP2.0降级重试 网络状况较好时,HTTP2.0多路复用,带来了性能上优势,但在网络不稳定时,HTTP1.1错误率低于HTTP2.0
- IP直连重试, 直接进行IP直连,防止域名解析导致的错误
- 超级管道重试, 利用超级管道,进行兜底重试,防止单个机房故障,进行异地容灾
3.6 其他
- 竞速连接 对于重要域名,使用TCP连接进行测试,选择最优的IP
- TLS1.3 TLS1.3相较之前版本,由2RTT降低为1RTT,降低了SSL握手失败的概率.
- 连接优化 预建连接,连接重建,备用/复合连接
4.成果
4.1 监控发现具体案例
案例1: 端上无限重试
灰度期间,播放记录接口,在极少数被劫持情况,证书被替换,导致触发SSLException,网络库的配置默认降级为
HTTP请求,但是业务方云控不允许使用HTTP,于是,引起了无限重试,导致单个用户短时间会上传几万条错误信息.
如果没有端上网络监控,类似这类偶发问题,是非常难复现和定位解决的.在APM上,我们首先通过报警提醒问题,再通过查询聚合信息缩小问题范围,最后通过详情信息解决问题.
案例2: 后端机房故障
后端武汉某个机房,上线新服务,但是,qlb健康检查失败 摘除了武汉所有前置机,但是后端没有第一时间发现该问题.APM及时进行了报警,并通知后台同学进行了处理.
后端服务链路复杂,可能出现报警遗漏.但是APM是基于用户真实体验,能够代表用户当前真实的网络请求状态
4.2 错误率下降趋势
爱奇艺APP的错误率,随着版本的持续优化,Android从最初5.3%,目前稳定在0.48%; IOS从最初4.63%,目前稳定在0.35%.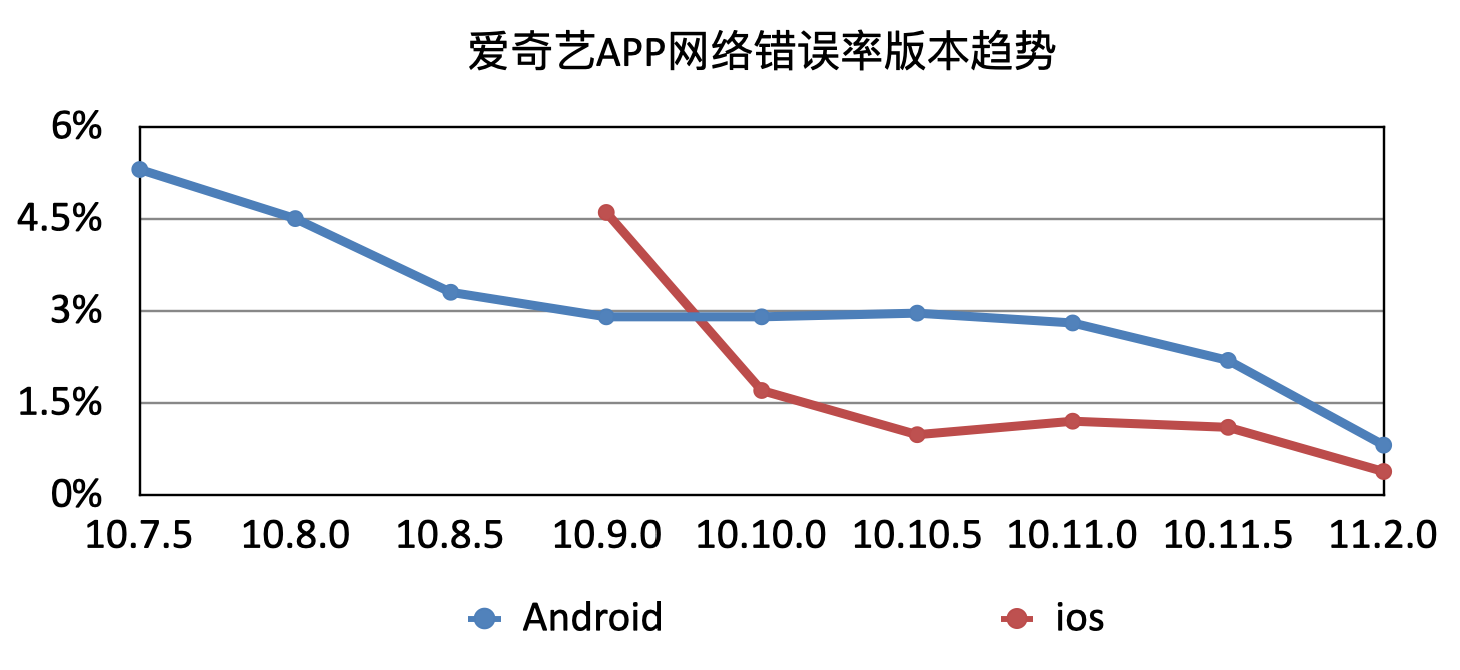
5.结尾
网络监控系统上线后,已落地爱奇艺APP各端,随刻、电影票、奇秀等独立APP. 经过多个部门的合作,使爱奇艺APP错误率有了较大幅度下降,并建立日常问题监控体系,为爱奇艺APP网络质量保驾护航.